ML
Machine Learning
We aim to develop mathematically grounded ML methodologies that remain robust, adaptive, and trustworthy in the presence of uncertainty. Our research is grounded on mathematical fundamentals from statistical and learning theory, providing a rigorous foundation for inference and learning.
Our work addresses fundamental methodological and practical challenges that arise when ML systems are deployed in real-world contexts, such as energy and health systems, biomedical informatics, industrial processes, and complex sensor-driven environments.
We design models with uncertainty quantification, offering not just predictions and prescriptions, but a measure of their reliability, alongside rigorous theoretical guarantees. This approach ensures the ability to operate safely and reliably in dynamic and high-stakes environments.
Our research integrates three complementary, theoretically grounded pillars:
- Robust and Adaptive Learning Theory: Focused on minimax frameworks and rigorous mathematical analysis, we devise machine learning methods with performance guarantees under challenging conditions like covariate shift and concept drift. This pillar encompasses evolving tasks and online adaptive learning, ensuring theoretical reliability even when conditions change.
- Probabilistic Machine Learning: Leveraging statistical and Bayesian theory, we develop and characterize probabilistic generative models. This provides a rigorous mathematical foundation to understand and model real-life data-generating processes, enabling calibrated uncertainty quantification and leading to descriptive, predictive, and prescriptive frameworks essential for reliable decision-making.
- Data-Centric and Model-Centric Machine Learning: Combining data-driven insights with model-based rigor, we address critical applied challenges, focusing on advanced time-series learning, weak supervision, handling missing data, and ensuring fairness and adversarial robustness in applied ML settings.
Together, these pillars aim to advance the generation of ML solutions that are theoretically principled and uncertainty aware, ensuring they are reliable, explainable, and deployable in dynamic, real-life environments subject to data complexity and missingness.
BCAM’s Machine Learning research tackles several methodological axes that jointly showcase the group’s distinctive and comprehensive approach to Machine Learning.
▹ Robustness and Learning Under Uncertainty
We develop minimax and probabilistic ML frameworks that provide rigorous theoretical guarantees for reliable predictive performance. This ensures systems remain robust even when deployed with data that is noisy, scarce, imbalanced, evolving, or subject to adversarial manipulation.
Key methodological directions include:
- Minimax Learning and Robust Classification: Developing optimal strategies for robustness against worst-case data scenarios and adversarial manipulation.
- Performance Guarantees Under Distribution Shift: Designing methods with theoretical resilience against covariate shift and concept drift.
- Fairness and Stability: Ensuring fairness is maintained even under unstable or uncertain data-generating processes.
- Uncertainty-Aware Robustness: Applying probabilistic learning techniques to handle challenges like data missingness and model uncertainty.
Examples: ML methods for evolving tasks with guarantees, fairness stability analysis, formal characterization of adversarial attacks on models and explanations.
▹ Adaptive and Online Learning in Dynamic Environments and Time-Series
Time-series Machine Learning is a central area of expertise at BCAM. We design algorithms capable of efficiently adapting and updating themselves as conditions change, which is critical for dynamic domains like energy forecasting, physiological process modeling, industrial monitoring, and complex sensor networks.
Research efforts and contributions include:
- Bayesian Time-Series Analysis: modeling temporal dependencies, quantifying uncertainty in forecasts, and performing reliable inference in dynamic environments.
- Time-series anomaly detection: via self-supervised representation learning and generative modeling
- Online and streaming time-series: prediction and classification, as well as classification, imputation, and forecasting in multivariate sensor data
- Elastic-, distance- and kernel-based time-series modeling and learning
- Learning and forecasting with hybrid (statistical and machine learning) dynamical system
- Adaptive strategies for concept drift
- Early and incremental classification for real-time systems
Examples: surveys on time-series anomaly detection, online DTW, adaptive load forecasting, selective imputation for sensor data, early and elastic classification, streaming novelty detection, time-series meta-learning.
▹ Probabilistic Machine Learning and Uncertainty Quantification
Many real-world problems require not only a description or prediction, but also a rigorous understanding of the confidence or uncertainty associated with such outcome. Our research in this area is rooted in probability and statistical theory, providing a solid mathematical bedrock for advanced ML methodologies with calibrated uncertainty quantification.
Our methodological contributions are structured around:
Foundational Generative Modeling:
- Developing Probabilistic Generative Models (e.g., Normalizing Flows, Variational Autoencoders) designed to understand the underlying data-generating process, enabling descriptive, predictive, and prescriptive frameworks.
- Designing Graphical and Structured Probabilistic Models (including Bayesian networks) for complex data dependencies.
Principled Treatment of Data Challenges:
- Handling Missingness and Data-Drift: Providing a principled treatment of missingness (with or without imputation) and data-distribution drifts using probabilistic methods.
- Weak and Noisy Supervision: Advanced learning under weak- or noisy supervision, addressing scenarios like learning from label proportions, positive-unlabeled data, or biased/unreliable annotators.
Algorithm Development and Scope:
- Efficient Inference: Creating efficient algorithms for learning and inference in high-dimensional and complex models: Variational Inference, Markov Chain Monte Carlo, Sequential Monte Carlo, etc.
- Broad Data Scope: Methodologies for modeling diverse data types, including continuous, discrete, ranking, and time-series data.
Examples: Bayesian classifiers from label proportions, Gaussian Processes, Normalizing Flows, probabilistic treatment models, semi-supervised multi-class learning.
▹ Trustworthy and Explainable Machine Learning
Our research contributes methodological advancements that make ML systems interpretable, reliable, and accountable for high-stakes decision-makers. This ensures trust and transparency from model development through deployment:
Key contributions focus on:
- Fairness, Stability, and Transparency: Developing methods and theoretical guarantees that ensure algorithmic fairness and model stability, particularly when data distributions are shifting or uncertain.
- Explainable AI for Complex Data: Creating explainable, statistical and Machine Learning models specifically tailored for complex data.
- Trustworthy ML: Rigorously analyzing the vulnerabilities of both machine learning models and their explanations (e.g., adversarial manipulation of explanations), for robust system design.
Examples: Explainability in time series, adversarial manipulation of explanations, fairness under shifting distributions and its stability analysis, feature attribution methods.
▹ Federated Learning of Classifiers and Probabilistic Models
We design distributed and decentralized algorithms for training classifiers and probabilistic models over heterogeneous, privacy-sensitive networks.
- Federated and decentralized learning algorithms
- Learning under non-IID, drifting, or adversarial data conditions
- Privacy and robustness in distributed systems
Examples: decentralized learning of probabilistic classifiers, learning over time-varying communication networks, robust aggregation under adversarial or unreliable nodes.
▹ Sequential Decision-Making Under Uncertainty
We research the mathematical grounds for designing intelligent agents that offer calibrated measures of predictive and prescriptive uncertainty, which is essential for systems operating in high-stakes environments, where actions must be taken based on imperfect, noisy and evolving information.
Our methodological focus revolves around reinforcement learning (RL) and control theory:
- Multi-Armed Bandits (MAB): Developing theory and algorithms for the optimal trade-off between exploration and exploitation in complex, real-world settings.
- Decision Making in Non-Stationary Environments: Extending classical decision-making under uncertainty for dynamic and non-stationary environments, to robustly adjust to drifting reward distributions and evolving dynamics.
- Multi-Objective and Contextual Optimization: Devising algorithms that can optimize for sequential and potentially conflicting goals (e.g., maximizing returns while minimizing uncertainty or risk) and integrate rich contextual information to enable informed sequential choices under uncertainty.
Examples: Online resource allocation and scheduling, adaptive clinical trial design, dynamic pricing algorithms.
▹ Unified Vision
By integrating robust theoretical learning, probabilistic modeling, time-series methodology, trustworthy ML, federated learning, and sequential decision-making, the BCAM Machine Learning research line provides a coherent and comprehensive scientific foundation for the safe and effective development and deployment of AI.
Our objective extends beyond advancing ML theory: we ensure these mathematically grounded methodological advances translate into reliable, interpretable, and high-impact applications across strategic domains, including energy, health, industry, and the environment.




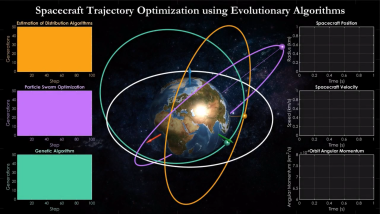
Hierarchical sequence optimization for spacecraft transfer trajectories based on the employment of meta-heuristics
Description: This video shows the simulation of hierarchical sequence optimization for spacecraft transfer trajectories based on the employment of meta-heuristics. Three types of evolutionary algorithms including ìGenetic Algorithmî, ìParticle Swarm Optimizationî and ìEstimation of Distribution Algorithmsî are used in optimal guidance approach utilizing low-thrust trajectories. Different initial orbits are considered for each algorithm while the orbits are expected to have the same shape and orientation at the end of space mission.
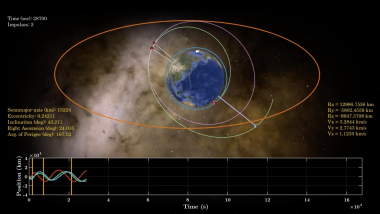
Multi-impulse Long-Range Space Rendezvous via Evolutionary Discretized Lambert Approach
Transfering satellites between space orbits is a challenging task. Due to the complexity of the space systems, finding optimal transfer trajectories requires efficient approaches. This video shows the simulation of the satellite motion in a space mission, where a new evolutionary algorithm is developed and utilized for the orbit transfer. The satellite performs multiple transfers between intermediate orbits until it reaches the desired destination. Novel heuristic mechanisms are used in the development of the optimization algorithm for spacecraft trajectory design. Simulation results indicate the effectiveness of the algorithm in finding optimal transfer trajectories for the satellite.
Understanding non-convex optimization problems and stochastic optimization algorithms
Contributions to the mathematical modeling of estimation of distribution algorithms and pseudo-boolean functions
Efficient Meta-Heuristics for Spacecraft Trajectory Optimization
Algorithms for large orienteering problems
Advances on time series analysis using elastic measures of similarity
K-means for massive data
Theoretical and Methodological Advances in semi-supervised learning and the class-imbalance problem
KmeansLandscape
Study the k-means problem from a local optimization perspective
Authors: Aritz Pérez
License: free and open source software
Placement
Local
PGM
Procedures for learning probabilistic graphical models
Authors: Aritz Pérez
License: free and open source software
Placement
Local
On-line Elastic Similarity Measures
Adaptation of the most frequantly used elastic similarity measures: Dynamic Time Warping (DTW), Edit Distance (Edit), Edit Distance for Real Sequences (EDR) and Edit Distance with Real Penalty (ERP) to on-line setting.
Authors: Izaskun Oregi, Aritz Perez, Javier Del Ser, Jose A. Lozano
License: free and open source software
Probabilistic load forecasting based on adaptive online learning
This repository contains code for the paper Probabilistic Load Forecasting based on Adaptive Online Learning
Authors: Veronica Alvarez
License: free and open source software
MRCpy: a library for Minimax Risk Classifiers
MRCpy library implements minimax risk classifiers (MRCs) that are based on robust risk minimization and can utilize 0-1-loss.
Authors: Kartheek Reddy, Claudia Guerrero, Aritz Perez, Santiago Mazuelas
License: free and open source software
Minimax Classification under Concept Drift with Multidimensional Adaptation and Performance Guarantees (AMRC)
The proposed AMRCs account for multivariate and high-order time changes, provide performance guarantees at specific time instants, and efficiently update classification rules.
Authors: Veronica Alvarez
License: free and open source software
Efficient learning algorithm for Minimax Risk Classifiers (MRCs) in high dimensions
This repository provides efficient learning algorithm for Minimax Risk Classifiers (MRCs) in high dimensions. The presented algorithm utilizes the constraint generation approach for the MRC linear program.
Authors: Kartheek Reddy
License: free and open source software
Double-Weighting for General Covariate Shift Adaptation
This repository provides efficient learning algorithm for Minimax Risk Classifiers (MRCs) in covariate shift framework.
Authors: Jose Segovia
License: free and open source software
BayesianTree
Approximating probability distributions with mixtures of decomposable models
Authors: Aritz Pérez
License: free and open source software
Placement
Local
MixtureDecModels
Learning mixture of decomposable models with hidden variables
Authors: Aritz Pérez
License: free and open source software
Placement
Local
FractalTree
Implementation of the procedures presented in A. Pérez, I. Inza and J.A. Lozano (2016). Efficient approximation of probability distributions with k-order decomposable models. International Journal of Approximate Reasoning 74, 58-87.
Authors: Aritz Pérez
License: free and open source software
Minimax Forward and Backward Learning of Evolving Tasks with Performance Guarantees
This repository is the official implementation of Minimax Forward and Backward Learning of Evolving Tasks with Performance Guarantees.
Authors: Veronica Alvarez
License: free and open source software